The simplest way to execute our tool is to provide a list of gene or protein identifiers and select organism / ID format from our list of supported databases. That's all it takes! You are then taken to a holding page until your calculation finishes. Depending on the server load, the calculation should be finished in under 30 minutes.
For user's convenience, we have implemented multiple id-types per organism.
Same submission form as with the manual submission, only in this case it is possible to upload custom universe. This allows different baseline to be used (whole proteome is used as a default) to calculate more precise enrichment results. You can access the custom-universe submission here.
As a part of the multiCM analysis, The GO analyser can be invoked for each of the submitted sets without the need of data re-submission. We also provide ID-type auto-detection based on the FASTA file labels. To start with the automated analysis, please click on a coloured "dot" to activate the details menu:
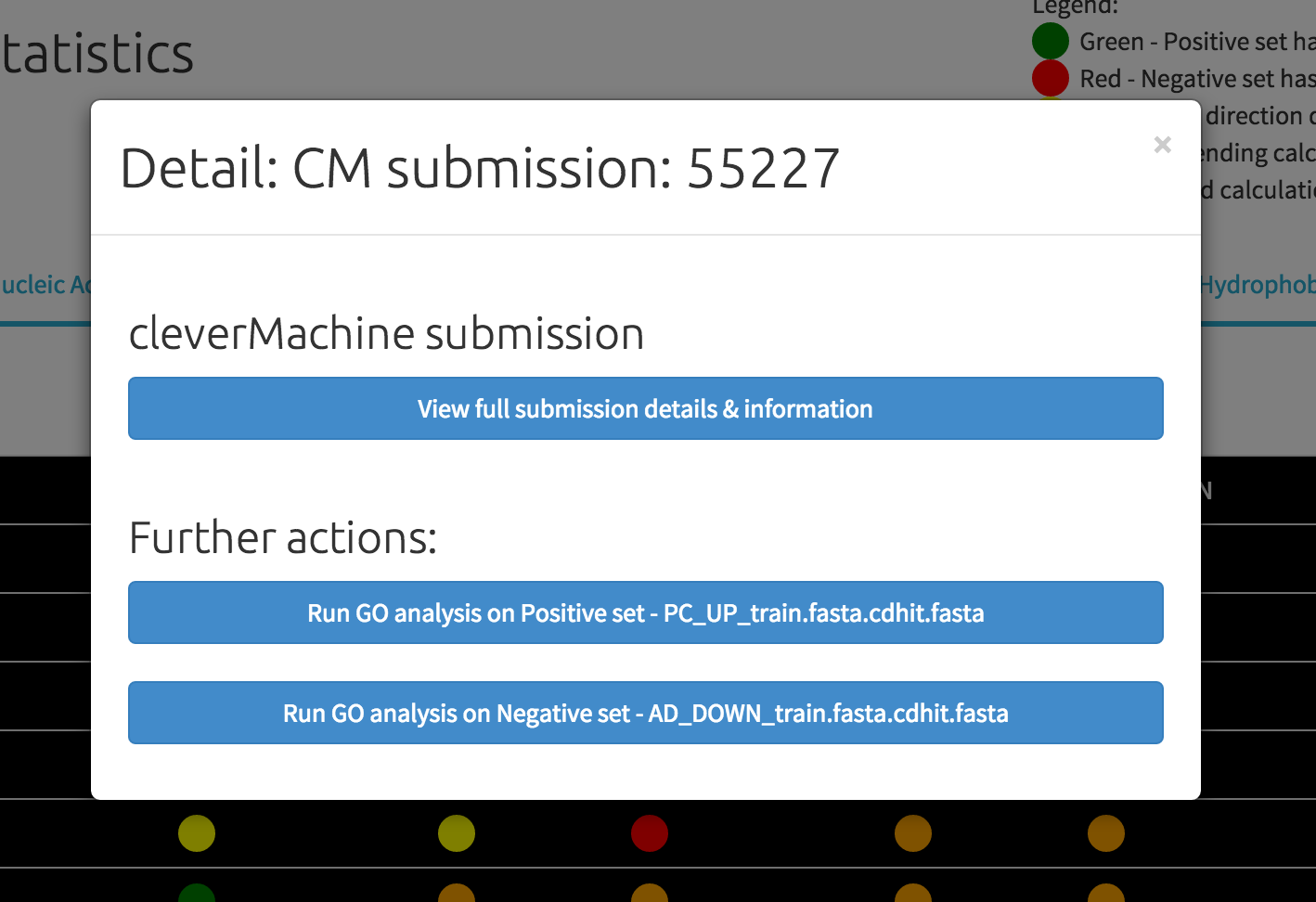
As each cleverMachine model contains two datasets, analysis can be launched for each of the sets. After selecting a set, user is presented with the auto-detection screen to determine which organism/ID system to execute. The ID detection system relies on either presence of the ID in a simple form, or using standardised UniProt FASTA headers.
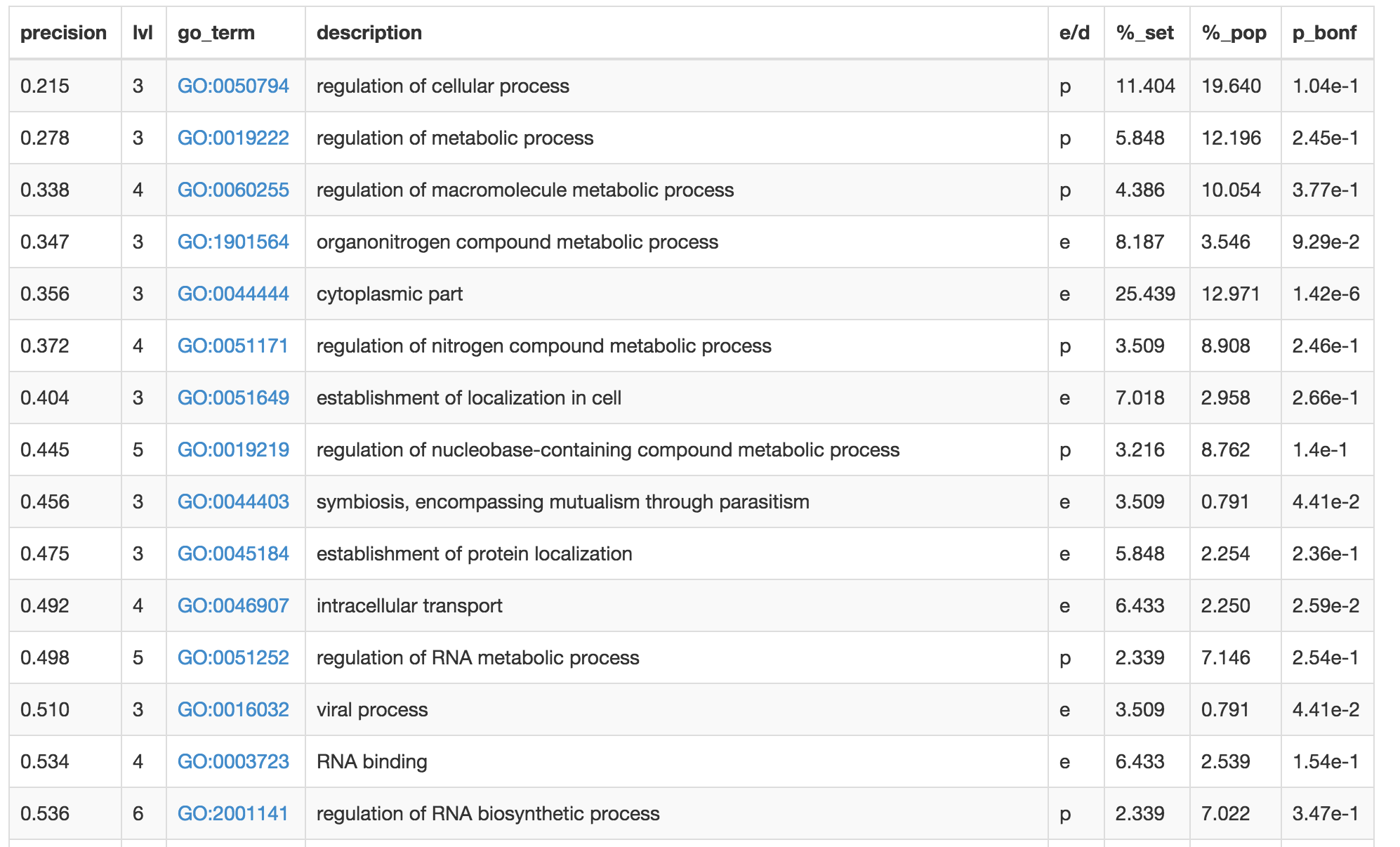
While the main structure of the enrichment table remains the same, we allow on-the-fly filtering and sorting of the output data.
For example, clicking on a column heading provides sorting by the selected column.
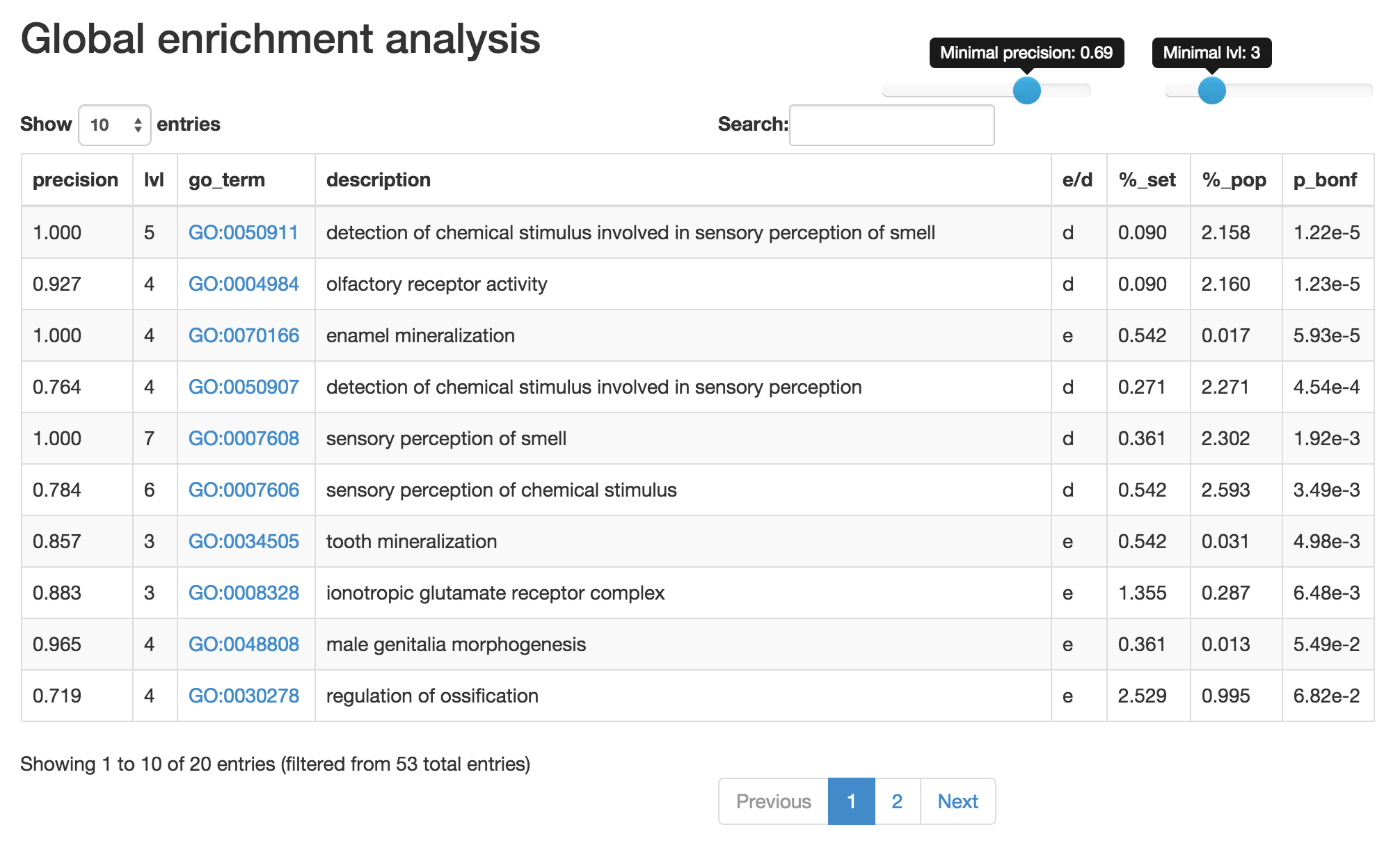
Using the sliders in the upper-right corner allows filtering of terms depending on their
depth in the GO graph and the term precision. This function is useful narrowing-down the list to more specific
terms is required. Often the most-specific terms provide the most relevant insight. The term precision is calculated
according to :
Herrmann C., Bérard S., Tichit L., SimCT: a generic tool to visualize ontology-based relationships for biological objects, Bioinformatics (2009) 25 (23): 3197-3198.
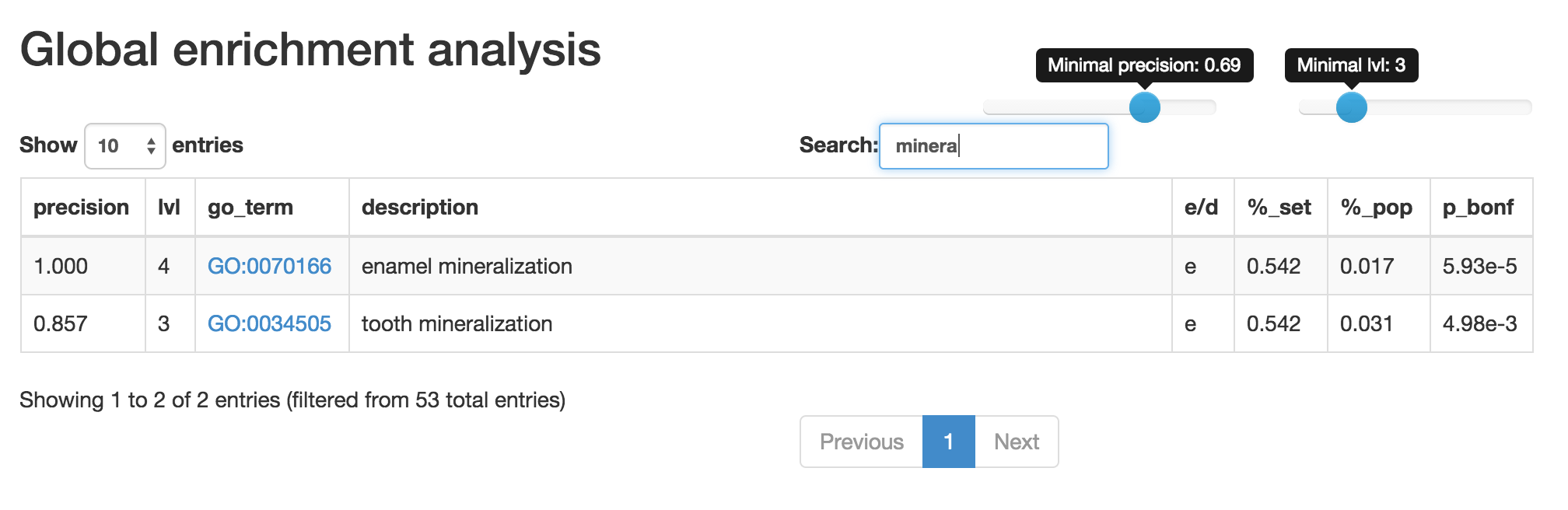
Free-text search field allows matching of the GO terms to the user-provided string. Only the entries for which the description is matching the search term remain on the list.
The GO graph builds on top of the annotation information and provides further insight into relationships of the individual GO terms and links them together based on their semantic similarity. Read more on how we calculate the semantic similarity strengths in the documentation.
The visualisation is interactive and reacts to the following virtual forces to show the result:
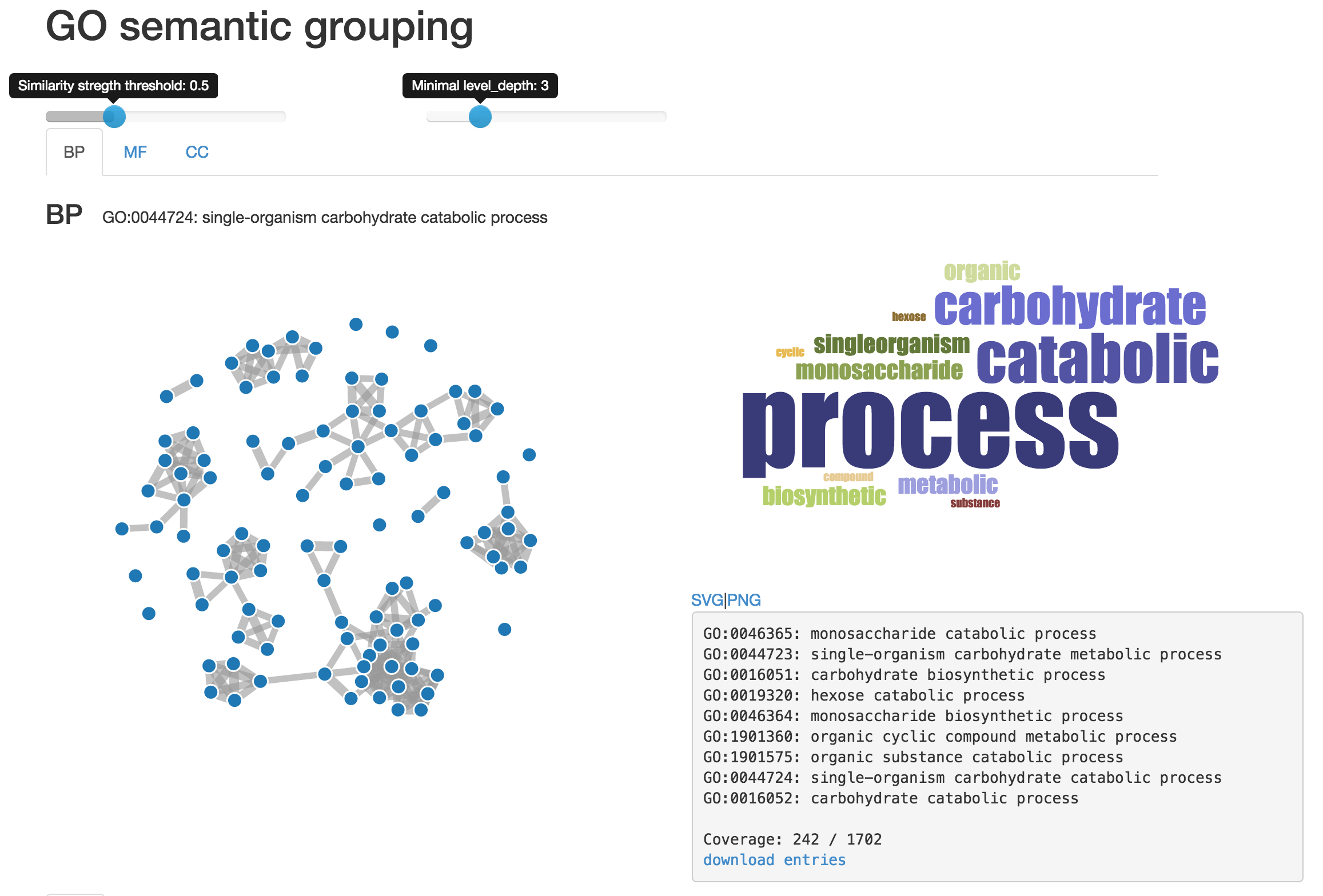

GO elements are connected to other nodes similar to them. This connection can have varying strenght and while we already take the spring strength into account for the visualisation, changing the similarity strenght threshold allows further pruning of the lower-score connections.
The level_depth provides high-pass filter for the elements of the graph - we are not filtering the connections but the actually the individual entries, same functionality as in the enrichment table.
The precision provides high-pass filter for the elements of the graph based on the term precisions - as it is the case with level_depth, we are not filtering the connections but the actually the individual entries, same functionality as in the enrichment table.
Another filter for the elements of the graph is p-value qualification of the entries for the graph.
The graph represents the GO terms as nodes with semantic similarity as connections between them. Both nodes and connections are filtered based on the settings provided above.
For each of the clusters, we provide basic visualisation of its contents. A cluster can be selected by clicking on any of its nodes, which activates the details side-panel. Cluster is simply defined as a set of noded that are connected to the selected node, either directly or through a proxy. A word-cloud is presented for each clusters, showing important words found in the GO term descriptions.
Alongside with the wordcloud, we also provide a listing of all of the entries present in the cluster.
Importantly, we also cross-reference the cluster contents with the original submission and provide
a set of entries from the original submissions that can be covered by the cluster's entries.
This allows downloading of the contents of each of the clusters.
We ensure that our algorithm works on latest versions of Mozilla Firefox and Google Chrome. We are relying on the latest and greatest of web technologies and we do not require any extra plugin installation.
As a consequence of the above, any other browser not mentioned above is not supported and may not provide full experience.
Also, should you experience any problems when uploading files, please ensure that your internet connection works properly and there are no proxies/firewalls blocking the transfer in between you and our servers.